
El concepto de DevOps puede resumirse como una cultura de trabajo que permite la comunicación y colaboración entre el desarrollo y la operación (de los términos en inglés «development» y «operations«).
Azure DevOps nos permite integrar esta cultura de trabajo en nuestros proyectos incluso de base de datos, a continuación presentaré el paso a paso para crear tu base de datos en un entorno de desarrollo que permita el control de versiones, integración continua y entrega continua.
En este artículo nos enfocaremos en el control de versiones e integración continua (del inglés continuous integration), en una próxima entrada, continuaremos con la configuración de un «release» para la entrega continua.
Los desarrolladores con la integración continua integran de manera frecuente su código a la rama principal de un repositorio común, lo que resulta en una reducción de tiempos y detección temprana de conflictos entre el código nuevo y el existente.
Para comenzar, se asumirá que se posee el conocimiento básico para crear un proyecto de Azure DevOps, además de un repositorio GIT para el control de versiones del proyecto. Si quieres más información al respecto puedes ver el curso «Azure DevOps Starter» en nuestro canal de YouTube NotJustBI.
Creando la solución
Una vez creado nuestro repositorio de GIT, clonaremos la solución en Visual Studio (VS):


Seleccionamos la ruta local para el directorio de GIT, y conectamos:

A continuación, creamos un proyecto de base de datos, basta con colocar «sql» en el buscador para localizarlo:

Se debe crear el proyecto en el directorio local de GIT, si ya se tenía creado previamente el proyecto de base de datos, se pueden copiar los archivos en este directorio:

Una vez creado el proyecto, y antes de comenzar a generar los objetos, una sugerencia es organizarlo con carpetas, siendo la raíz el nombre del esquema, y crear subcarpetas para identificar el tipo de objeto, como tablas, procedimientos almacenados (stored procedures), vistas, funciones, entre otros. Es importante acotar que al generar la base de datos, los objetos se organizarán como acostumbramos a verlos en SQL Server Management Studio (SSMS), sin embargo, al crear una solución de VS tenemos la libertad de darle un orden que nos permita localizar más fácilmente los elementos de nuestros proyectos.
La solución que hemos creado contiene un proyecto de nombre «DB» el cual será el nombre de nuestra base de datos, adicionalmente generamos una carpeta de nombre «dbo» que será nuestro esquema por defecto, finalmente adicionamos tres carpetas para los objetos de tipo «vistas«, «procedimientos almacenados» y «tablas«:

Desde VS también podemos visualizar y realizar consultas al servidor donde se alojará nuestra base de datos, para este caso práctico se utilizará un servidor local en mi máquina. Para ingresar solamente debemos abrir el explorador de objetos de SQL Server:


Creando una tabla
Crear objetos en un proyecto de base de datos de VS resulta muy sencillo, además de que contamos con herramientas para ayudarnos a mantener la solución, realizando cambios y compilando en busca de errores de sintaxis. Para crear una tabla, se hace click derecho sobre la carpeta que generamos para este tipo de objeto dentro de nuestro esquema «dbo»:

Aparecerá una ventana para asignar un nombre al elemento, además, se pueden ver todos los tipos de objetos disponibles:

Al crear la tabla se mostrarán dos secciones, una de código donde se puede crear o editar el elemento con lenguaje SQL, y una de diseño, donde se puede crear o editar de forma más visual, similar a SSMS.

Si queremos crear un foreing key con otra tabla que se encuentre en el proyecto, en el lado derecho de la sección de diseño hacemos click derecho sobre «Claves externas«, y seleccionamos «Agregar nueva clave externa«:

Se va a generar en la sección de código una línea plantilla, donde sustituiremos los nombres de tablas y campos según corresponda a nuestro caso, como lo siguiente:

Publicando el proyecto
Una vez tengamos creados todos los elementos de nuestra base de datos, y decidamos publicarlo finalmente, será necesario construir un pipeline en Azure DevOps para realizar la de integración continúa.
Para ello, vamos a generar una arquitectura que considere un equipo de trabajo generando el control de versiones con GIT, cada cual con una rama individual, con un proceso de integración grupal a la rama principal o «master«.
A continuación, indicaremos el paso a paso para la actualización de cambios con el control de versiones:
1. Desde el proyecto de VS, crearemos una rama local para integrar el proyecto creado en el repositorio que conectamos inicialmente:


2. Una vez creada la rama, iremos a la sección «Cambios» en Team Explorer, para subir la rama creada y los cambios al repositorio remoto:

Colocamos un mensaje que identifique la actualización que realizaremos, y seleccionamos «Confirmar todo«:

3. Nos movemos a la sección «Sincronización«, para actualizar los cambios en el repositorio remoto, ubicamos los cambios que queremos insertar:


4. Finalmente, ingresamos al portal «dev.azure.com» y verificamos que se creara correctamente la rama y se insertaran los cambios que enviamos:

Creando un pipeline de integración contínua
En este punto ya tenemos el proyecto en nuestra rama remota, ahora bien, crearemos un pipeline para la integración continua cuando se haga un «pull request» hacia la rama master, lo que tendrá como resultado un objeto o «artefacto» de creación de la base de datos en base al código.
Primero, seleccionaremos la pestaña «Pipelines» de la sección del mismo nombre en el portal de Azure DevOPs:

Una vez allí, seleccionamos «Create Pipeline«, y utilizaremos la opción del editor clásico:

Seleccionamos como fuente un repositorio GIT :

Luego como plantilla podemos seleccionar «.NET Desktop«, haciendo click en aplicar:

En la edición del pipeline, eliminaremos las opciones de la plantilla que no utilizaremos para esta implementación, quedando los siguientes pasos:

La configuración de las tareas quedaría de la siguiente forma:

Pasamos a la pestaña «Triggers» donde habilitaremos la opción de integración continua, e indicaremos que se realizará desde la rama «master»:

Finalmente, salvamos el pipeline en la ubicación por defecto:

Con esto estaría configurado nuestro pipeline. Ahora realizaremos un cambio en el proyecto, para probar su ejecución.
Actualizando y publicando el proyecto
Hacemos una modificación en una de las tablas, como por ejemplo, agregamos una descripción de un campo:

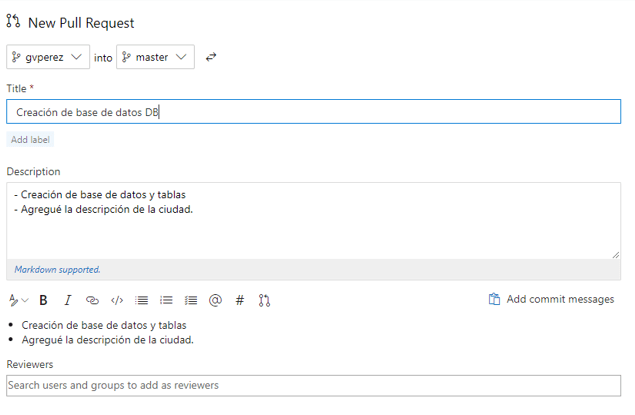
Realizamos la actualización del proyecto desde VS con el mismo procedimiento de pasos arriba (cambios, sincronización, insertar), nos dirigimos a la web, y hacemos un «pull request»:

Realizamos los comentarios correspondientes al cambios, asignamos a la persona que los revisará, y una vez aprobados, completaremos el «merge» con la rama «master«, lo que actuará de «trigger» para el pipeline que hemos construido:

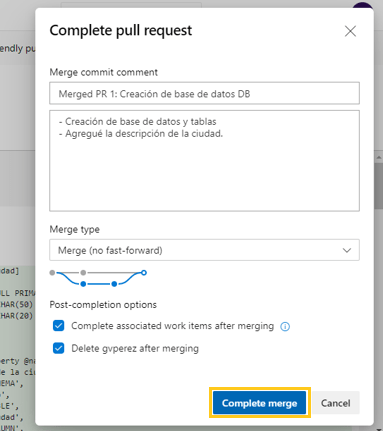
Luego de esto, comenzará a ejecutarse automáticamente el pipeline, generando un «artefacto«, que será el archivo para la creación de la base de datos.
Estado «en cola»:

Estado «en proceso»:

Estado «completado con éxito»:

«Artefacto» creado:

En resumen, hemos generado nuestro proyecto de base de datos desde VS, creado un ambiente de control de versiones con GIT, y construido un pipeline de ejecución automatizada de integración continua de los cambios que realice el equipo de desarrollo en el proyecto.
Espero que les resulte de utilidad, y nos estaremos leyendo en próximas entradas.
Por favor, si tienes algún comentario, duda o sugerencia, no dudes en contactarnos a través de nuestro correo: info@notjustbi.com
5 comentarios